

OCR文字检测之DBNET
摘要
基于分割的场景文字检测方法往往更准确,特别是针对卷曲的文字,在使用基于分割的方法时,二值化的后处理非常重要。作者提出了Differentiable Binarization模块,不仅简化了二值化方法而且效果更好。
介绍
由于场景文字的大小形状的多样,使用基于分割的检测方法往往更好,但是大部分基于分割的方法需要复杂的后处理将像素级别的结果组合成文字行,在预测时开销往往很大。例如PSENet使用连续尺度扩张的方式后处理;LSAE计算像素之间的特征距离来聚类。
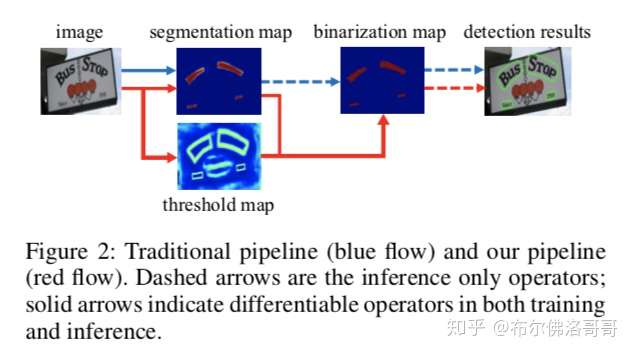

大部分检测模型用上图的方式做后处理(蓝色箭头)。第一种,设置一个固定的阈值,把分割图转化成二值化图,然后用一些启发式的方法例如聚类把像素处理成文字行;而作者的方法(红色箭头),把二值化的操作放到网络里面同时优化,这样每个像素点的阈值都可以自适应地预测,这样就可以更好地区分前景与背景。常规的二值化方法是不可微的,我们提出了Differentiable Binarization,一种近似的方法来做二值化,这种方法在与分割网络一起使用时是完全可微的。
DB module有四个优点:
1.作者的模型在5个基准数据集上表现得更好,包括处理横向、纵向和卷曲文字。
2.作者的模型比之前的方法快得多,得益于DB可以生成高可靠的二值图,显著地简化了后处理。
3.即使使用轻量级的骨架网络,DB表现也很好,跟Resnet-18组合使用效果提升很多。
4.DB模块在inference过程中可以去掉,不会有更多的内存/时间开销。
相关工作
基于回归的方法
基于分割的方法
快速场景文字检测方法
方法
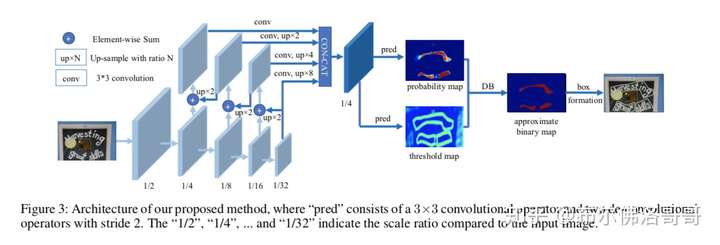
网络架构如上图,首先将图像输入到一个特质金字塔骨架网络;然后金字塔特征上采样到相同的尺度并连接到一起去生成特征图F;接着使用F来生成概率图P 和阈值图 T;最后通过P、T计算近似二值图 。都会用label去监督训练P、T和 ,其中P 和 使用相同的label。在测试阶段可以轻松地使用P或者 生成bounding box。
二值化
标准二值化
分割网络生成概率特征图 ,需要将概率特征图转成二值特征图,其中1代表文字区域 其中t是预设的阈值,(i,j)指定了特征图上的坐标。
可微分二值化
标准二值化是不可微分的,因此不能跟分割网络一起训练,为了解决这个问题,作者提出可微分二值化:
其中 是近似的二值特征图;T是从网络中学习到的自适应阈值,k是放大因子,经验上取值为50。这种方法不仅可以将文字从背景中区分出来,同时也可以将两个靠近的文字区域分开。
为了解释DB为何可以提升效果,我们可以从梯度的角度去解释,我们以交叉熵loss为例,
设 作为DB 方法,其中 , 是正样本loss, 是负样本loss
计算梯度
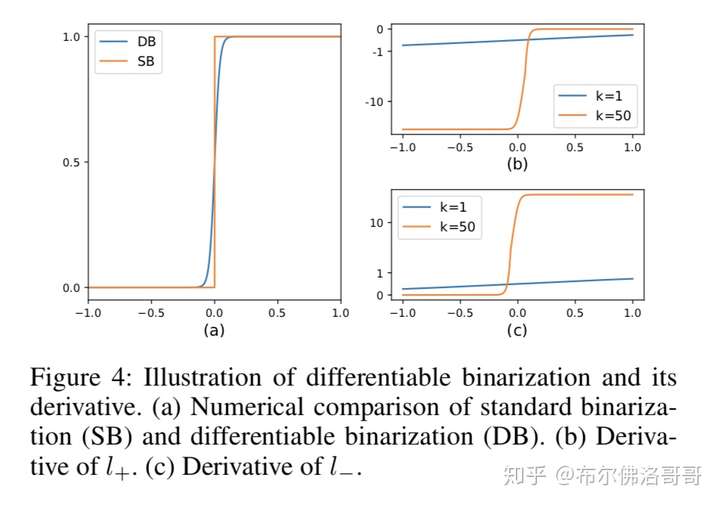
1) 梯度可以通过k放大
2)在大部分预测出错的情况下,放大后的梯度都很明显( ),因此帮助进一步优化模型而且可以输出更加有区分度的预测,而且P的梯度被T影响。
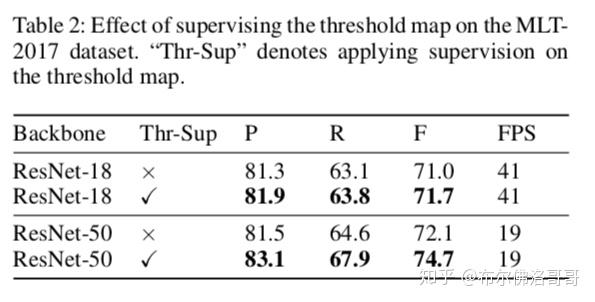
自适应阈值
阈值图看起来有点像文字边界图,但是两者的出发点和用途是不一样的。阈值图就算没有做监督也可以高亮标出文字边界区域,这表明高亮边界的阈值图对最终结果有益。因此作者给高亮边界的阈值图加上了监督。从用途的角度考虑,文字边界图是用来进来文字实例的分割,而作者是用来做二值化的。

可变卷积
可变卷积可以给模型提供可变化的感受野,有着极端比例和尺度的文字区域特别受益于这种卷积方式。
标签生成
概率图的标签生成是受到PSENET的启发,所有文字区域都被描述成分割区域的集合:
其中n是顶点的个数。正样本区域是通过使用Vatti clipping算法将G收缩到 ,收缩偏移量D是通过周长L和面积A计算的: ,其中r是收缩比例,经验上设置为0.4。
相同的我们也要给阈值图生成标签。使用相同的偏移量D将G膨胀到 。然后将 之间的区域作为文字边界,阈值图的标签就是计算该区域到到G的最近距离。

优化
损失函数 可以表示成概率图损失 、二值图损失 和阈值图损失 的加权求和:
根据经验设置成1.0和10。
使用的是二值交叉熵损失,为了平衡正负样本,我们就使用了hard negative minging
是采样后的数据集,正负样本比例为1:3。
是 区域中预测值与标签的
,其中 是 中像素的索引, 是阈值图的标签。
在预测阶段,使用概率图或者近似概率图都可以生成文字的bounding box,两者生成的结果差异不大。为了提升模型的效率,我们使用概率二值图,这样阈值分支就可以抛弃了。文字框生成的流程主要包括三步:
(1)使用固定阈值(0.2)给概率图或者近似概率图做二值化。
(2)从二值图中获取连通域(收缩后的文字区域)。
(3)使用偏移量 来膨胀文字收缩区域。
,其中 是收缩区域的面积, 是收缩区域的周长, 经验上设置到1.5。
实验
数据集
SynthText
人工合成的数据集,包含800k张图片,8k张背景图,作者仅仅用来预训练。
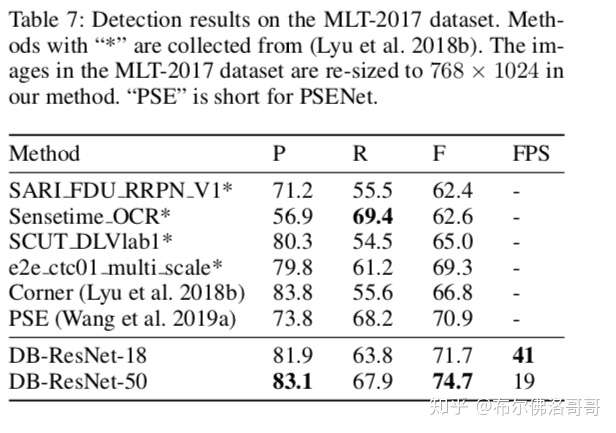
MLT-2017 dataset
多语言的数据集,9种语言展示6种脚本。7200张训练数据,1800张验证数据,9000张测试数据。我们使用训练数据和验证数据来finetune。
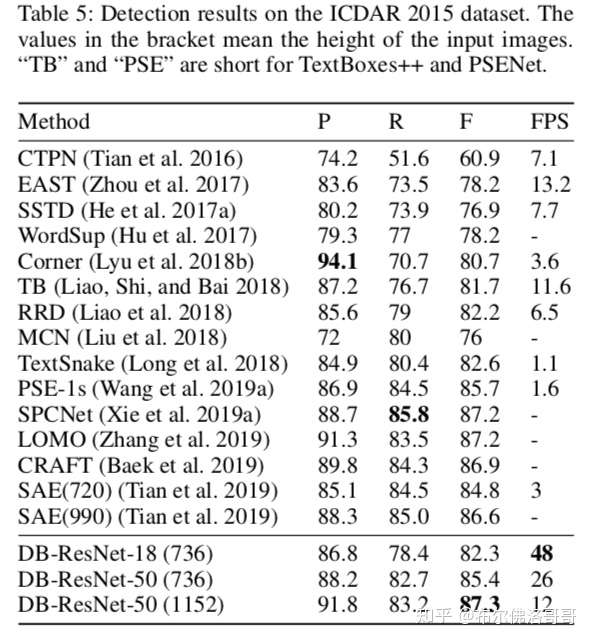
ICDAR 2015 dataset
由google glassees采集,分辨率720*1280,1000张训练数据,500张测试数据。标注是单词级别的。
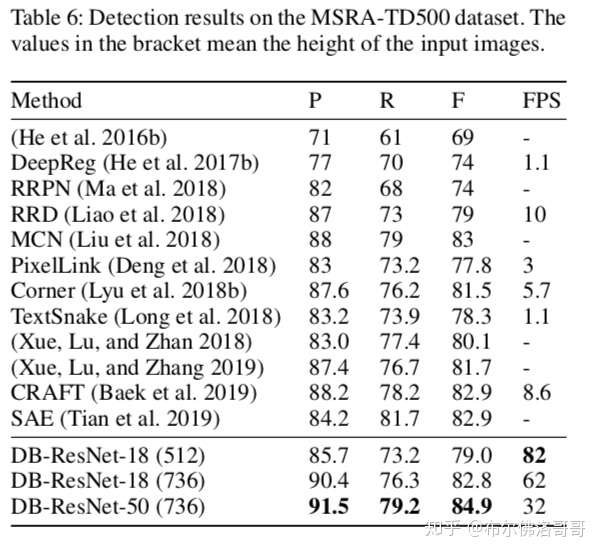
MSRA-TD500 dataset
中英文双语的数据集。300张训练数据,200张测试数据。标注是文字行级别的。跟之前的方法一样,我们把HUST-TR400中的400张训练数据也加进来了。
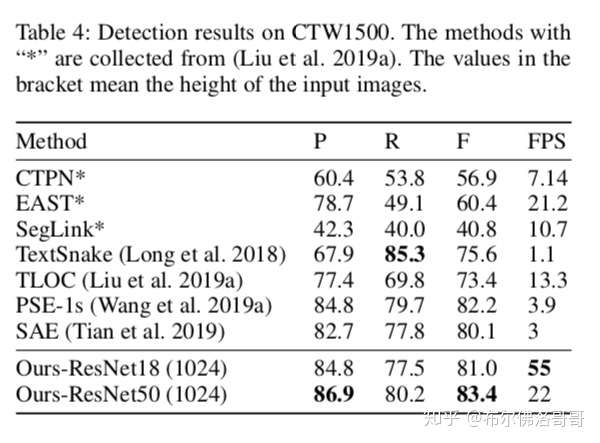
CTW1500 dataset
卷曲文字数据集,1000张训练数据,500张测试数据。标注是文字行级别的。
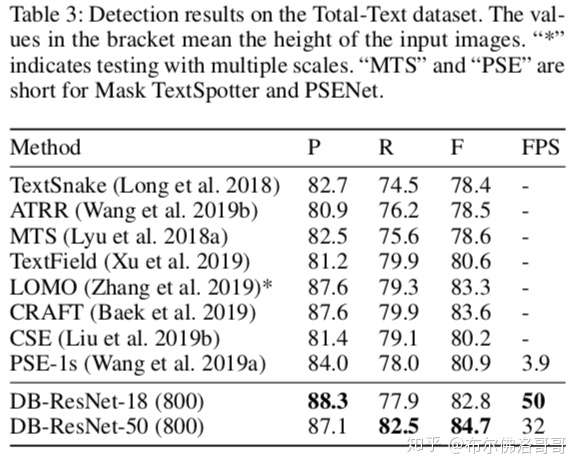
Total-Text dataset
包括各种形状的文字,水平的、多方向的和卷曲的。1255张训练数据和300张测试数据。标注是单词级别的。
实现细节
先使用SynthText预训练100k次迭代,继续在真实数据上 finetune 1200个epochs。训练batch size为16。使用poly lr,当前学习率为初始学习率乘上 ,初始学习率为0.007,power为0.9。
数据增广用到三种方法:(1)随机在 之间旋转;(2)随机裁剪;(3)随机翻转;所有图片最终都转到640*640。
在测试阶段,我们保持原图的比例,针对不同的数据设置一个固定的图像高度。batch size为1,单张1080ti GPU,单线程。总耗时包括模型前向和后处理,后处理耗时占总体的30%。
消融实验
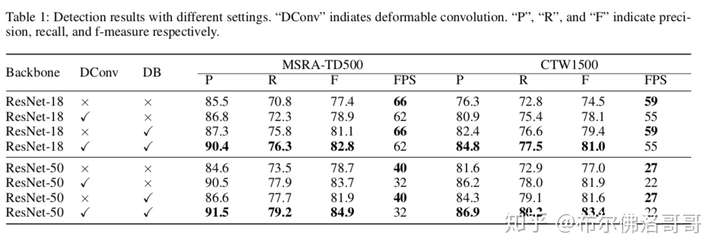
在MSRA-TD500 和 CTW1500上展示可微二值化、可变卷积和不同骨干网络的区别。
与之前的模型对比
卷曲文字
多朝向文字
多语言
局限
当一个文字目标在另一个文字目标中心的时候,无法检测。“text inside text”也是常见的问题。
结论
基于Resnet50的模型在多个数据集上的表现一致超过SOTA;而Resnet18也能达到速度和精度的均衡。
文章来源:知乎